
O estudo ”The Illusion of Thinking” talvez seja um jeito de dizer que sim.
Em meio à disputa acirrada entre OpenAI, Google, Anthropic, Meta e tantos outros, a Apple tem mantido um perfil mais discreto na corrida dos modelos de IA generativa.
Enquanto as big techs lançam modelos cada vez mais impressionantes em reasoning, multimodal, agents e copilots, a Apple publica um estudo denso, técnico e — talvez — defensivo: The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models. Deixo o link para o artigo original em inglês ao final desse post
A pergunta natural é:
Será que a Apple está sugerindo que, na verdade, o mercado está superestimando a capacidade atual de raciocínio dessas IAs?
Vamos destrinchar o que o estudo mostra — e o que ele pode estar, sutilmente, tentando comunicar.
O que a Apple estudou: Reasoning Models sob o microscópio
O estudo parte de uma constatação válida:
A maioria das avaliações de IA hoje mede apenas o acerto final. Não mede o processo de raciocínio.
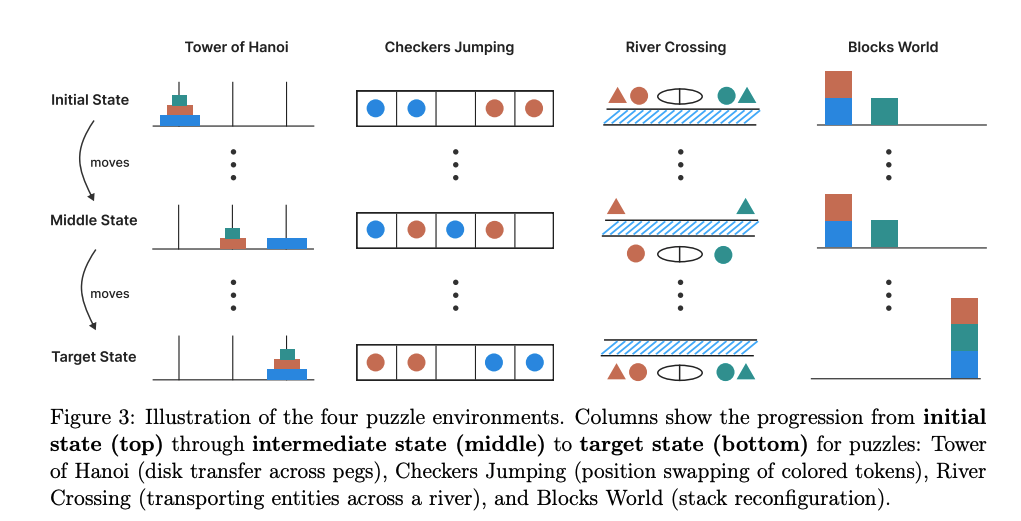
Para tentar analisar o pensamento dos modelos, os pesquisadores da Apple criaram um ambiente controlado, com quatro tipos de problemas clássicos de planejamento e lógica:
- Torre de Hanoi: resolver o desafio de mover discos entre pinos com regras restritas.
- Checker Jumping: trocar a posição de peças coloridas obedecendo regras de movimento.
- River Crossing: transportar pares de atores/agentes sem violar restrições de segurança.
- Blocks World: reordenar blocos empilhados em configurações-alvo.
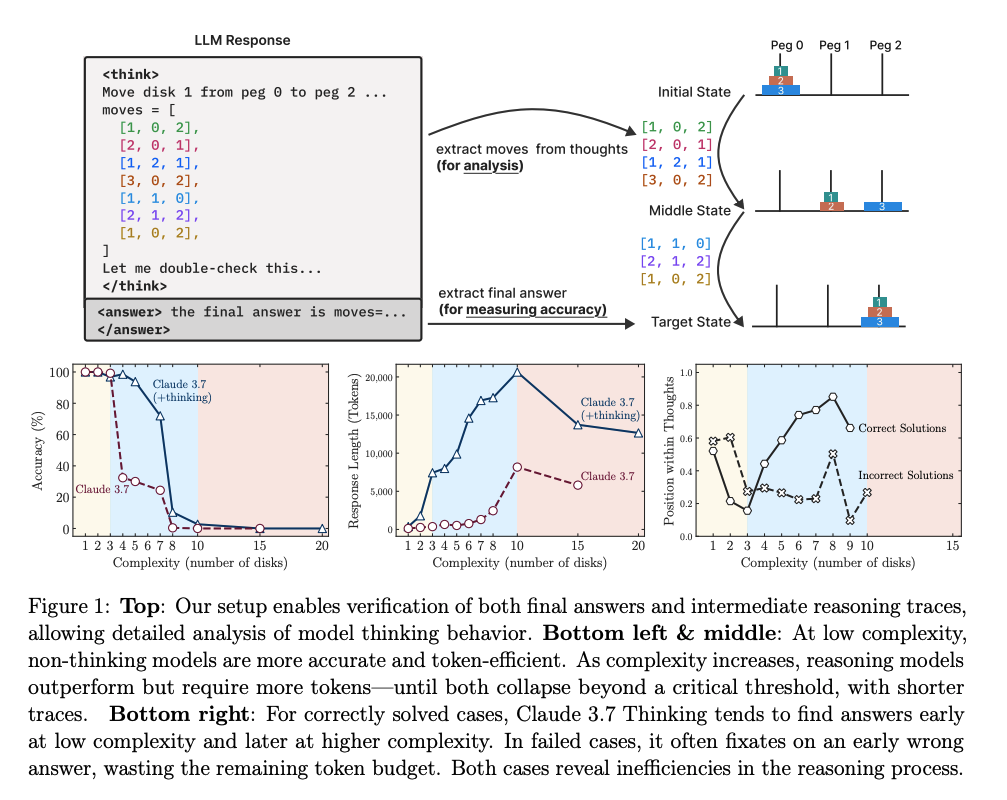
Esses puzzles têm algo que benchmarks como o MATH500 não oferecem:
- Controle preciso da complexidade.
- Ausência de poluição por dados de treinamento (data contamination).
- Capacidade de analisar não só o acerto, mas o caminho até o acerto.
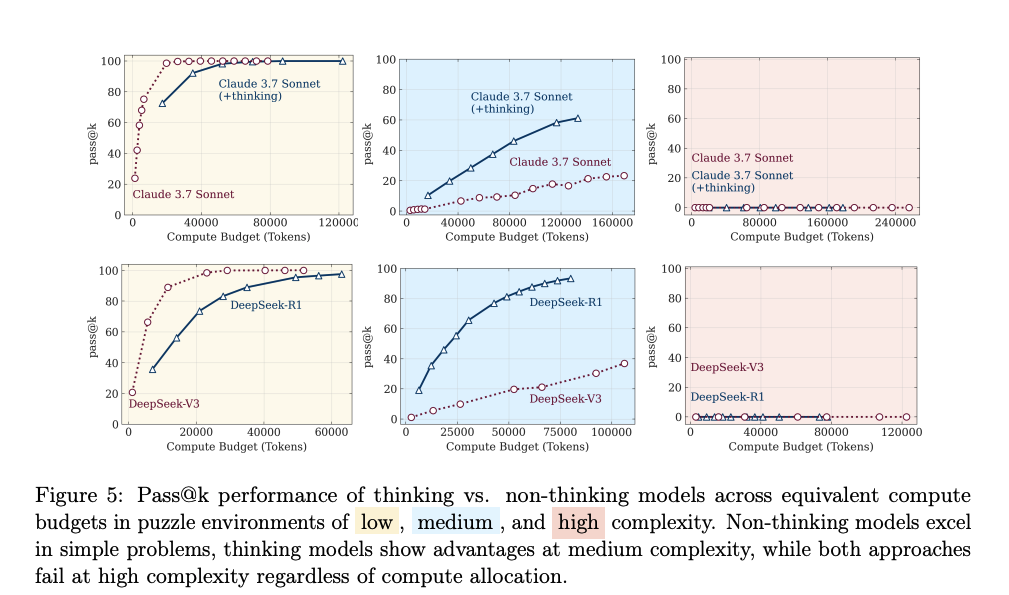
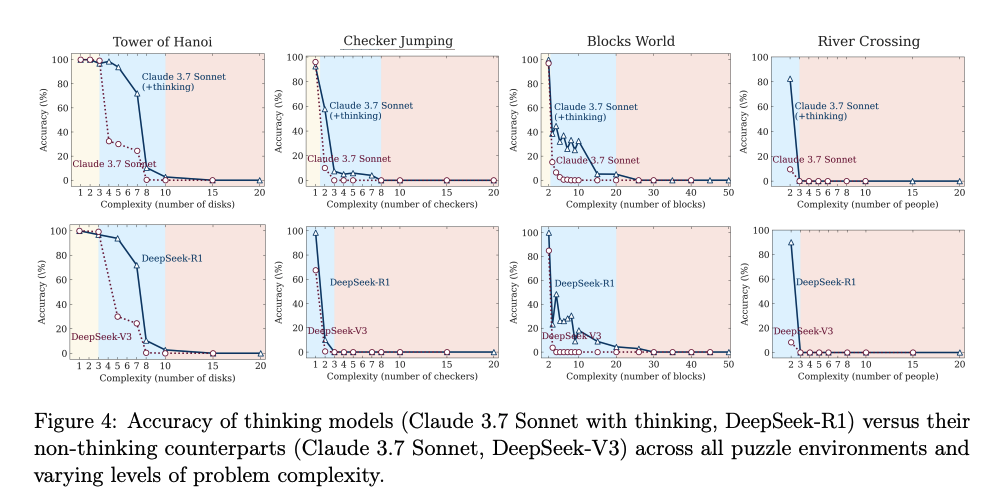
As três zonas de performance que os modelos mostram
O estudo revela um padrão bastante robusto nos Large Reasoning Models (LRMs), como Claude 3.7 Thinking, DeepSeek-R1 e o3-mini:
1 – Baixa complexidade (problemas simples):
- Modelos padrão (sem Chain-of-Thought) se saem tão bem ou até melhor.
- São mais eficientes: precisam de menos tokens e computação.
- Exemplo: resolver um Tower of Hanoi com 3 discos é trivial para ambos, mas o LRM gasta muito mais “pensamento” do que o necessário.
2 – Complexidade intermediária:
- Os LRMs começam a mostrar superioridade.
- A estratégia de “pensar em etapas” (Chain-of-Thought + Self-Verification) consegue gerar soluções onde os modelos padrão começam a falhar.
- É aqui que os LRMs parecem realmente “raciocinar”.
3 – Alta complexidade (problemas difíceis):
- Ambos colapsam.
- A precisão cai para perto de zero.
- Pior: mesmo tendo orçamento de tokens suficiente, os LRMs passam a pensar menos quando o problema fica mais difícil.
- Um possível limite estrutural de escalabilidade cognitiva nos modelos atuais.
O curioso fenômeno do overthinking
A Apple explorou também o comportamento interno das thinking traces — o caminho de pensamento que o modelo gera até chegar a uma resposta.
Descobertas interessantes:
- Em problemas simples, o modelo encontra a resposta certa rapidamente… mas continua explorando caminhos errados depois. (Como aquele amigo que revisa tanto o trabalho pronto que acaba bagunçando o que já estava certo).
- Em problemas médios, primeiro tenta soluções erradas e só depois acerta.
- Em problemas difíceis, não encontra nenhum caminho correto, e cai como um castelo de cartas.
O “pensamento” não é sempre adaptativo. Muitas vezes é apenas uma enumeração exaustiva de possibilidades, limitada por ruído e falta de supervisão interna real.
Mesmo com o algoritmo pronto, eles falham
O estudo também testou uma hipótese crucial:
Será que o problema está em descobrir o caminho ou em executar os passos?
Resposta surpreendente:
- Mesmo quando o algoritmo de solução era explicitamente fornecido no prompt (ex.: sequência de passos do Tower of Hanoi), os LRMs (Large Reasoning Models) ainda falhavam ao tentar executar.
- O colapso ocorre no mesmo ponto de complexidade.
- Isso sugere limitações não apenas de descoberta, mas de manipulação simbólica e execução lógica passo a passo.
O que a Apple realmente quer dizer com tudo isso?
Agora entramos na parte geopolítica da IA:
- É fato que OpenAI, Google DeepMind, Anthropic e até startups menores têm investido pesado na escalada da cognição artificial.
- Enquanto isso, a Apple — que até agora manteve seus LLMs majoritariamente fechados — começa a publicar estudos sugerindo que talvez essa escalada esteja batendo em paredes mais cedo do que o hype admite.
Em outras palavras:
“Não estamos tão atrás. Na verdade, ninguém ainda chegou lá de verdade.”
Claro que o estudo é sério, rigoroso, importante.
Mas é também uma peça de narrativa no xadrez estratégico da corrida de IA.
Conclusão: um avanço? Ou um recado?
O trabalho da Apple cumpre uma função dupla:
- Do ponto de vista científico: mostra claramente limitações dos LRMs em tarefas de raciocínio estruturado, mesmo com estratégias sofisticadas de thinking tokens e self-reflection.
- Do ponto de vista estratégico: insinua que a corrida pelo general reasoning pode ser bem mais complexa e lenta do que o mercado, os investidores e as manchetes sugerem.
Em resumo:
Talvez The Illusion of Thinking não seja apenas o título do paper.
Pode ser também a forma como a Apple está nos dizendo: “Não acreditem que os outros estão tão longe na frente.”
Fontes:
Shojaee et al., The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity (Apple, 2025) – Link do paper


